Category: Neo4J
-
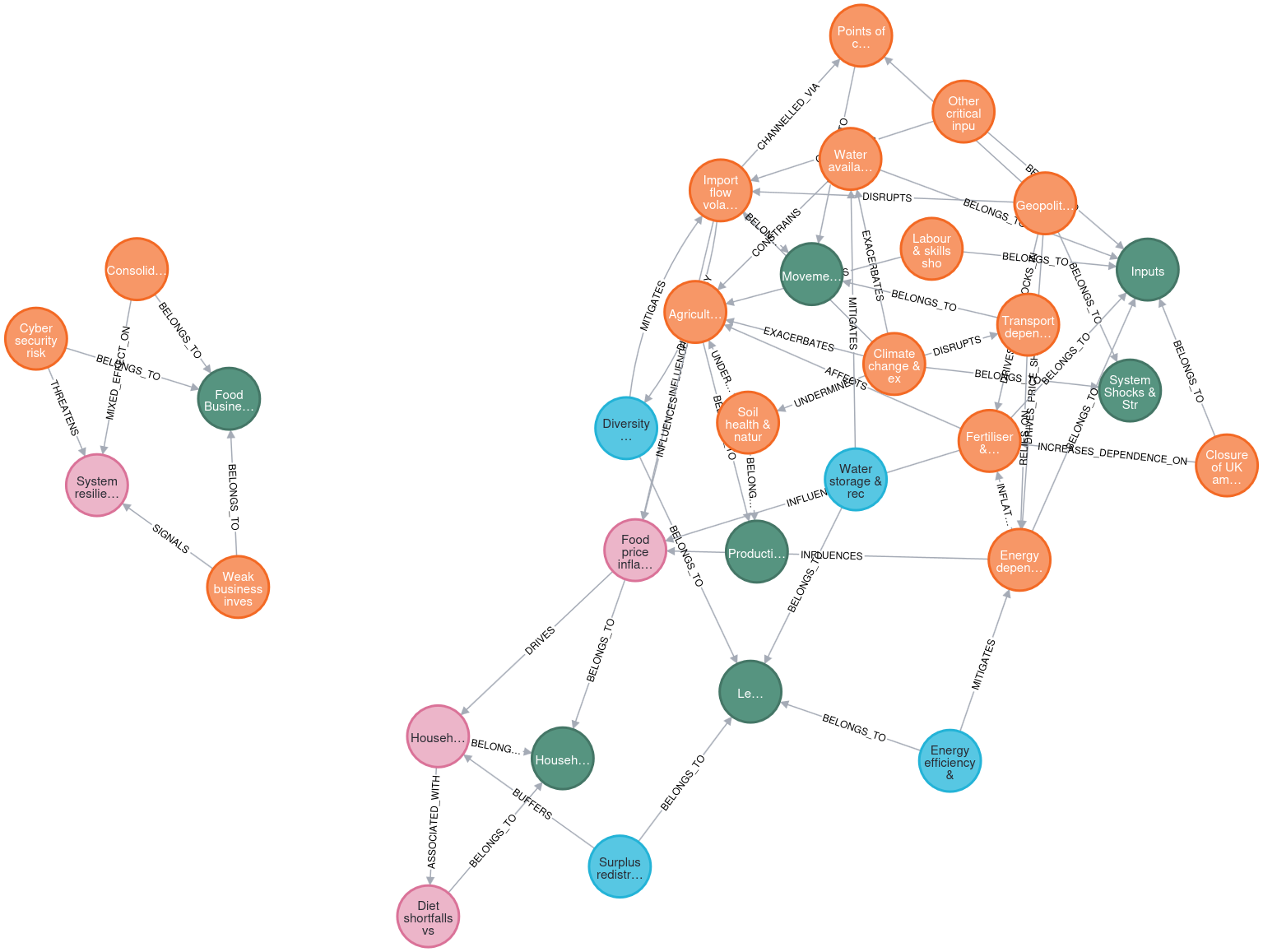
Using AI for systemic risks in food systems
I have long had an interest in systemic risks and failure. How a system can come apart and fail is at last as interesting as how they work, and applying complex systems methods to understand how systems are vulnerable to failure is something I would like to spend more time on. With that in mind…
-
Updated Daniel Morgan Network
I have processed more of the Daniel Morgan data, and thus have an updated network of the data. Below is a visualisation of the data produced by extracting the network structure from Neo4J using R and iGraph, then saving the network as a gexf file and importing into Gephi. The network is more complete but…
-
What do you do with the Panama Data?
The released Panama data comes in the form of a Neo4J database, or the files that you can make one with, seems to me a little tricky to do much with. There is no detail beyond attributes of the different entities, so that limits us to looking at the relationships alone and it is hard…
-
Daniel Morgan Murder
After listening to the Daniel Morgan podcast, Untold, I became really interested in the murder investigation. To help me follow it I started building a network of all the key people, organisations, and events in the case. The networks this produces can be seen here,and you can keep up-to-date with the progress on the network…
-
Panama Revisted
The people over at The International Consortium of Investigative Journalists have updated the released panama data. Its not clear to me if that is more data than they had already released, or that this time it is a ready made Neo4J database. They provide two versions of the database, Windows and Mac. Its easy to get…
-
Java Panama Papers Neo4J Network Generator
Further to the first attempt at importing the Panama Papers network data into Neo4J I did a very quick Java program that greats an embedded Neo4J database. It needs a bit of checking as it finds nodes that have the same node_id. Which I assume is some sort of mistake in the program or the…